
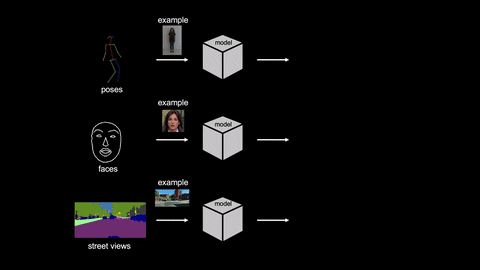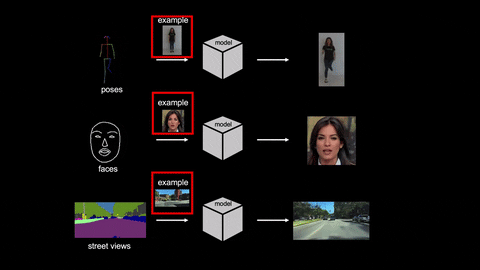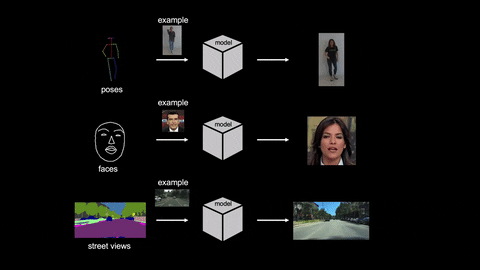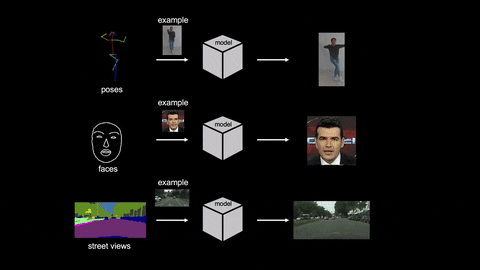
Recently, Nvidia has published a paper entitled “Few-shot Video-to-Video Synthesis” in which it is illustrated that they have developed a new AI that can make videos based on an existing video and an image.
That is if a person is dancing in a video and we have an image of another person then this AI can imitate the moves of the person in the existing video by replacing with the second person in the image to generate a new video.
Video-to-video synthesis (vid2vid) aims at converting an input semantic video, such as videos of human poses or segmentation masks, to an output photorealistic video.
Researchers, Nvidia Corporation
This technique is called to be a video-to-video synthesis. Researchers from the Nvidia corporation also published videos and code on Github.
The researchers found two major problems while designing AI. First is that it requires a lot of training data, various poses and scenes are required. While the second is that the learned model has limited generalization capability.
In the paper, researchers have proposed a few-shot vid2vid framework where the AI is able to develop low-resolution videos so far. The AI can develop never seen videos using a single image of the subject. The AI is based on a novel adaptive network weight generation scheme
[responsivevoice_button]






